what to estimate, recover, preserve
Breaking the Speed Limit
Fast statistical models with Python 3.14, Numba, and JAX
From a statistician's workflow: validate first, then accelerate the bottleneck.

Make the statistical task testable; then accelerate the measured bottleneck.
1Simulate
➜
2Validate
➜
3Find bottleneck
➜
4Pick tools
1
Simulation Makes Correctness Testable
Real data often lacks known ground truth for method behavior. Simulation creates a controlled setting to test power, calibration, and agreement.
null, alternative, hard or extremecases
readable Python/NumPy implementation
power, calibration, agreement
data flow, loops, algebra, repetition, memory
suitable for your task
Rule: Speedups are trusted only after validation passes.
2
Decisions Before Timing
| Question | Decision before measuring speed |
|---|---|
| Statistical target | estimator, test statistic, or stopping criterion |
| Simulated truth | labels, effect size, or nominal alpha |
| Acceptance criteria | exact match, numerical tolerance, or calibration |
| Failure mode | code bug, method breakdown, or out-of-memory |
| Timing scope | compile, transfer, allocation |
| Cost drivers | samples (n), features (p), or repeats (R) |
3
Validation Checks Passed
Speedup results verified using these criteria:
✓K-means agreement: max relative inertia difference well below the tolerance.
✓Permutation equivalence: same test statistic, same p-value definition, same resampling stream; max |p diff| < tolerance.
✓Statistic difference: max |stat diff| < tolerance across the validation grid.
✓Null calibration: estimated type-I error within MC uncertainty of nominal α = 0.05.
AI
AI for Scale, Statistician for Science
AI Automates Execution
- Algorithmic implementation
- Scenario-grid orchestration
- Automated metadata capture
- Visual synthesis of results
- Curation of research artifacts

AI assistant automating experiment tasks
Statistician Owns Inference
- Defining estimands & objectives
- Validating distributional assumptions
- Validation criteria
- Establishing rigorous benchmarks
- Deciphering edge cases & outliers
- Authoring scientific conclusions

Statistician making scientific decisions
4
Two Workloads, Two Bottleneck Patterns
K-means = Iterative Fitting
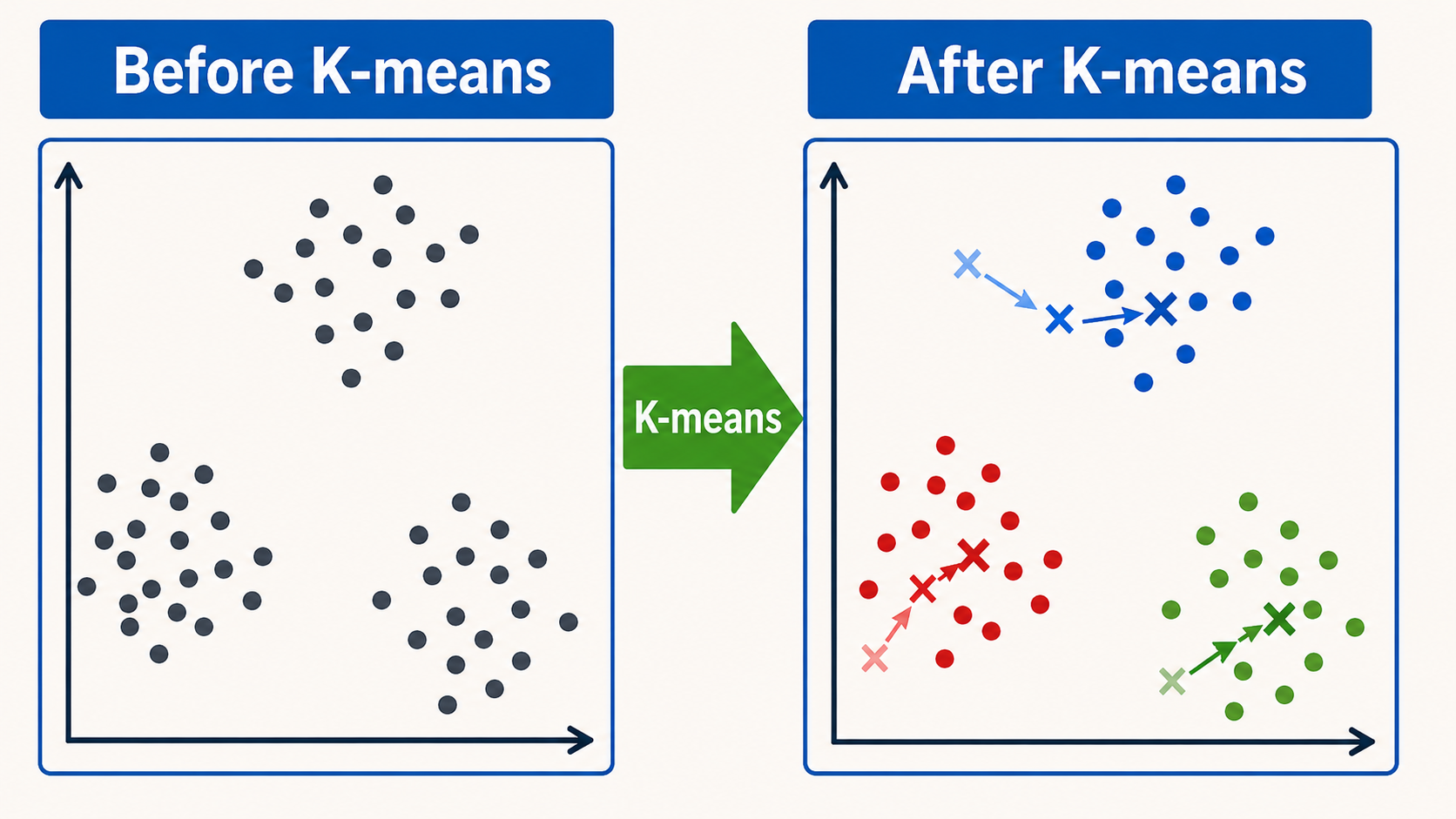
Sequential statePairwise metricsMemory allocations
Permutation = Resampling Inference

Shared-memory concurrencyVectorized resamplingLinear algebra
Validation criteria:
K-means Match cluster assignments by fixing seeds and convergence thresholds.
Permutation Same W, same statistic, same p-value formula.
5
Performance Depends on Workload Structure
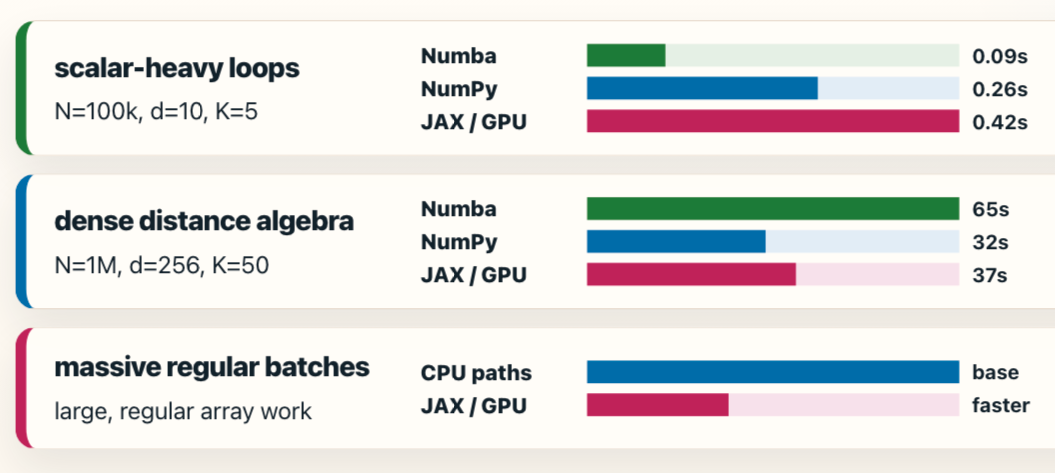
K-means: Workload Shape Determines the Tool
- • Scalar-heavy loops: Numba excels via LLVM-compiled execution.
- • Dense algebra: NumPy dominates via optimized BLAS kernels.
- • Massive data batches: JAX/GPU wins on SIMT throughput.
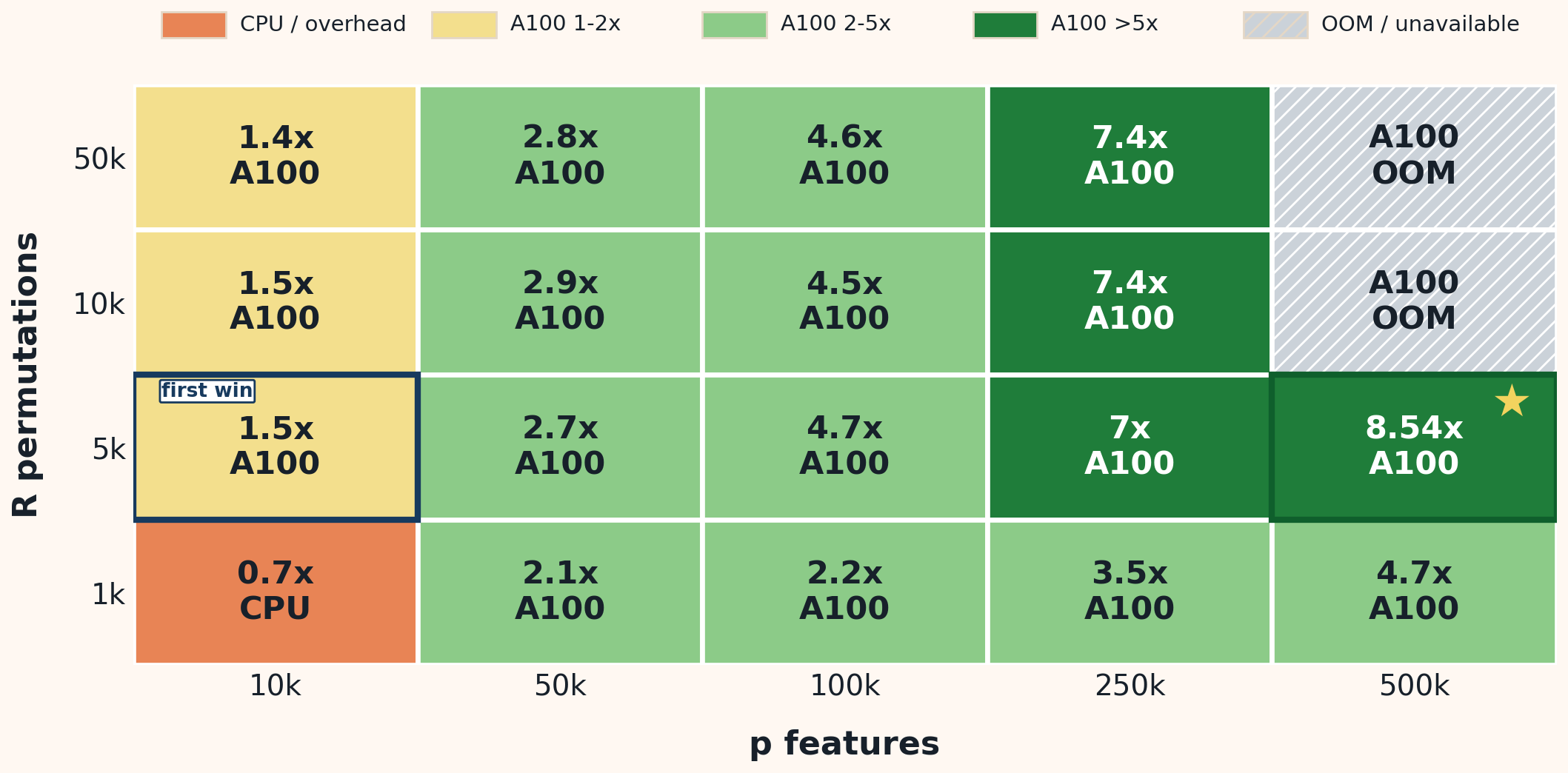
Permutation: GPU Scaling via Vectorized Batching
- Infrastructure Requirement: High-concurrency batching and fused reductions
- Observed Speedup: up to 8.54× for n=5k, p=500k, R=5k, using a matched CPU matrix baseline vs. A100 streamed end-to-end path.
- Operational Boundaries: Explicit OOM profiling for high-dimensional tensors
6
Diagnostic & Intervention
Diagnostic Matrix: Profiling Signature vs. Solution
Validation FailureAudit target & numerical stability
Scalar-Heavy LoopsJIT Compilation (Numba)
Dense Matrix OperationsVectorized BLAS (NumPy)
Embarrassingly Parallel TasksShared-Memory Threading
Massive Tensor BatchesSIMT Acceleration (JAX/GPU)
Bandwidth-Bound WorkloadFused & Streamed Reductions
7
Validated Tool Mapping
Aligning identified computational bottlenecks with targeted software frameworks, independent of hardware benchmarking.
8
Standardized Reporting
✓Validation Criteria: Explicit statistical targets and acceptance
thresholds
✓Compute Environment: Local prototyping vs. server-grade CPU / GPU
✓Execution State: Transparent reporting of cold starts, warm runs, and JIT
compilation
✓Memory Overhead: Accounting for data transfer, allocation, and garbage
collection
✓Failure Modes: Explicit documentation of OOM events and hardware
incompatibilities
✓Tool Parsimony: Deploying the simplest framework that preserves the target
statistic