The linear mixed-effect model (LMM) is a statistical model that accounts for both fixed effects and random effects in a linear regression model. It is used for modeling data where observations are not independent or identically distributed.
Consider a dataset {y,X,Z} with n samples, where y∈Rn is the vector of response variable, X∈Rn×p is the matrix of p independent variables, and Z∈Rn×c is another matrix of c variables. The linear mixed model builds upon a linear relationship from y to X and Z by y=fixedZω+randomXβ+errore,
where ω∈Rc is the vector of fixed effects, β∈Rp is the vector of random effects with β∼N(0,σβ2Ip), and e∼N(0,σe2In) is the independent noise term.
Let Θ denote the set of unknown parameters Θ={ω,σβ2,σe2}. Under the framework of EM algorithm, we can treat β as a latent variable. Below is the directed acyclic graph below for our model.
Figure 1. The directed acyclic graph for the linear mixed-effect model. The shaded nodes are observed variables and the unshaded nodes are latent variables. The arrows indicate the conditional dependencies.
The points indicate the parameters.
The plate indicates that the variables inside the plate are replicated n times.
The EM algorithm is an iterative algorithm that alternates between the E-step and the M-step until convergence. In the following sections, we will first find the posterior distribution of β given y and Θ^ in the E-step and calculate the Q function. Then we will find the ML estimator of Θ which is used in M-step. Finally, we will calculate and track the marginal data log-likelihood ℓ(Θ) to check the convergence of the algorithm.
Statistical Inference in LMM
Complete Data Log-Likelihood
The complete data log-likelihood is given by ℓ(Θ,β)=logp(y,β∣Θ)=logp(y∣β,Θ)+logp(β∣Θ)=−2nlog(2π)−2nlogσe2−2σe21∥y−Zω−Xβ∥2−2plog(2π)−2plogσβ2−2σβ21βTβ
Statistical Inference in E-Step
The E-step is to compute the expectation of the complete data log-likelihood with respect to the conditional distribution of β given y and Θ: Q(Θ∣Θold)=Eβ∣y,Θoldℓ(Θ,β)
Therefore, we need to find the posterior distribution of β given y and Θ. However the posterior distribution of β can not be obtained directly. Instead, by applying Bayes' rule, we have p(β∣y,Θ)=p(y∣Θ)p(y∣β,Θ)p(β∣Θ)∝p(y∣β,Θ)p(β∣Θ)∝exp{−21(y−Zω−Xβ)T(σe2In)−1(y−Zω−Xβ)}×exp{−21βT(σβ2Ip)−1β}∝exp{−21(β−μ)TΓ−1(β−μ)}
where Γ=(σe2XTX+σβ2Ip)−1 and μ=ΓXT(y−Zω)/σe2. And, the posterior distribution of β is β∣y,Θ∼N(μ,Γ). [1]
Thus, we have Q(Θ∣Θold)=Eβ∣y,Θold[logp(y,β∣Θ)]=Eβ∣y,Θold[logp(y∣β,Θ)+logp(β∣Θ)]=Eβ∣y,Θold[−2nlog(2π)−2nlogσe2−2σe21∥y−Zω−Xβ∥2−2plog(2π)−2plogσβ2−2σβ21βTβ]=−2n+plog(2π)−2nlogσe2−2plogσβ2−2σβ21tr(Γ)−2σβ21μTμ−2σe21(∥y−Zω∥2+tr(XΓXT)+μTXTXμ−2(y−Zω)TXμ)
Note that E[βTβ]=tr(V[β])+E[β]TE[β]=tr(Γ)+μTμ and E[(Xβ)T(Xβ)]=tr(XΓXT)+(Xμ)T(Xμ).
Statistical Inference in M-Step
M-step is to maximize the Q function with respect to Θ, which is equivalent to set the partial derivatives of Q with respect to Θ to zero. Thus, we have ∂ω∂Q⇒ω^∂σβ2∂Q⇒σ^β2∂σe2∂Q⇒σ^e2=−σe21ZT(y−Zω−Xμ)=:0=(ZTZ)−1ZT(y−Xμ)=−2σβ2p+2σβ41(tr(Γ)+μTμ)=:0=ptr(Γ)+μTμ=−2σe2n+2σe41(∥y−Zω∥2+tr(XΓXT)+μTXTXμ−2(y−Zω)TXμ)=:0=n1(∥y−Zω∥2+tr(ΓXTX)+μTXTXμ−2(y−Zω)TXμ)
Statistical Inference in Incomplete Data Log-Likelihood
Let Σ=σβ2XXT+σe2In be the covariance matrix of y, then the conditional distribution of y∣Θ is N(Zω,Σ). The incomplete data log-likelihood is given by ℓ(Θ)=logp(y∣Θ)=−2nlog(2π)−21log∣Σ∣−21(y−Zω)TΣ−1(y−Zω)
When ∣Δℓ∣=∣ℓ(Θ,β)−ℓ(Θold,β)∣<ε, the algorithm is considered to be converged, where ε is a small number.
The EM Algorithm: n >= p
E-step
The E-step is to compute the following expectations:
β^=μold
where Γ=(σe2XTX+σβ2Ip)−1 and μ=ΓXT(y−Zω)/σe2.
To simplify the calculation of Γ, we use the eigenvalue decomposition of XTX to accelerate the calculation of Γ. Let XTX=QΛQT, where Q is an orthogonal matrix and Λ=diag{λ1,…,λp} is a diagonal matrix with the eigenvalues of XTX on the diagonal. Then we have Γ=(σe2XTX+σβ2Ip)−1=(σe2QΛQT+σβ2Ip)−1=Q(σe2Λ+σβ2Ip)−1QT
where (σe2Λ+σβ2Ip)−1 is a diagonal matrix. The inverse of a diagonal matrix is the reciprocal of the diagonal elements.
M-step
The M-step is to maximize the expectation of the complete data log-likelihood with respect to Θ: Θ=argΘmaxQ(Θ∣Θold)
We have ω^σ^β2σ^e2=(ZTZ)−1ZT(y−Xβ)=p1(tr(Γ)+∥β∥2)=n1(∥y−Zω^∥2+tr(ΓXTX)+∥Xβ∥2−2(y−Zω^)TXβ)
where tr(Γ)tr(ΓXTX)=trQ(σe2Λ+σβ2Ip)−1QT=tr(σe2Λ+σβ2Ip)−1=i=1∑pσe2+σβ2λiσβ2σe2=trQ(σe2Λ+σβ2Ip)−1QTQΛQT=trQ(σe2Λ+σβ2Ip)−1ΛQT=i=1∑pσe2+σβ2λiλiσβ2σe2
Incomplete Data Log-Likelihood
However, we can not calculate the log∣Σ∣ and Σ−1 in likelihood directly since they would cause numerical overflow[2]. Instead, we use the eigenvalue decomposition of XXT to calculate the log determinant of Σ[3]. Let XXT=Q~Λ~Q~T, where Q~ is an orthogonal matrix and Λ~=diag{λ~1,…,λ~n} is a diagonal matrix with the eigenvalues of XXT on the diagonal. Then we have log∣Σ∣Σ−1=log∣σβ2XXT+σe2In∣=i=1∑nlog(σβ2λ~i+σe2)=(σβ2XXT+σe2In)−1=(σβ2Q~Λ~Q~T+σe2In)−1=Q~(σβ2Λ~+σe2In)−1Q~T
where (σβ2Λ~+σe2In)−1 is a diagonal matrix. The inverse of a diagonal matrix is the reciprocal of the diagonal elements.
Therefore, incomplete data log-likelihood is given by ℓ(Θ)=−2nlog(2π)−21logtr(σβ2Λ~+σe2In)−21(y−Zω)TQ~(σβ2Λ~+σe2In)−1Q~T(y−Zω)
where Q~ is the orthogonal matrix in the eigenvalue decomposition of XXT and Λ~ is the diagonal matrix with the eigenvalues of XXT on the diagonal.
Pseudocode
The EM algorithm is an iterative algorithm that alternates between the E-step and the M-step until convergence. The algorithm is summarized as follows:
Check ∣Δℓ∣=∣ℓ(Θ(t+1))−ℓ(Θ(t))∣<ε for convergence. If converged, stop. Otherwise, continue.
Return results.
The EM Algorithm: n < p
Since XTX is a p×p matrix and XXT is a n×n matrix, when n<p, it's easier to calculate the inverse of the latter. Therefore, we use the Woodbury matrix identity to simplify the calculation of Γ.
Let U=σe2σβ2XT and V=X, we have (σe2XTX+σβ2Ip)−1XT=XT(σe2XXT+σβ2In)−1
Let Γ~=(σe2XXT+σβ2In)−1
then we can use the eigenvalue decomposition of XXT to accelerate the calculation of Γ~. Also, it's obvious that XTΓ~=ΓXT and β^=μ~=XTΓ~(y−Zω)/σe2
Eigenvalue decomposition
Let XXT=Q~Λ~Q~T, where Q~ is an orthogonal matrix and Λ~ is a diagonal matrix with the eigenvalues of XXT on the diagonal. Then we have Γ~=(σe2Q~Λ~Q~T+σβ2In)−1=Q~(σe2Λ~+σβ2In)−1Q~T
where (σe2Λ~+σβ2In)−1 is a diagonal matrix. The inverse of a diagonal matrix is the reciprocal of the diagonal elements.
We can update tr(XXTΓ) as follows: tr(XXTΓ)=trQ~Λ~Q~TQ~(σe2Λ~+σβ2In)−1Q~T=trQ~Λ~(σe2Λ~+σβ2In)−1Q~T=i=1∑nσe2+σβ2λ~iλ~iσβ2σe2
Since the rank of XXT and XTX are equal (to the number of non-zero eigenvalues), when n<p, we have tr(Γ)⇒σβ2=i=1∑pσe2+σβ2λiσβ2σe2=i=1∑nσe2+σβ2λ~iσβ2σe2+(p−n)σβ2=p1(tr(Γ)+∥μ∥2)=p1(tr(Γ~)+∥μ~∥2+(p−n)σβ2)
Pseudocode
The EM algorithm when n<p is summarized as follows:
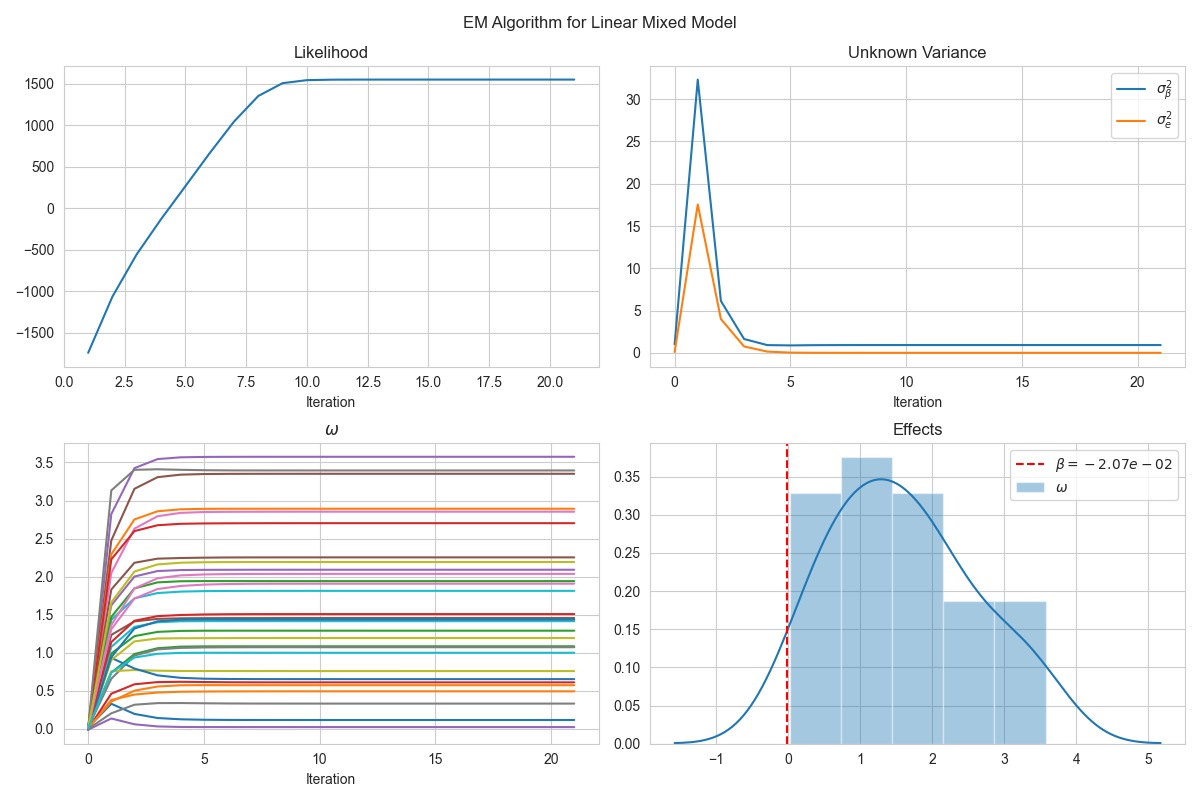
The results below are obtained by running the EM algorithm on a generated dataset.
The results in code are obtained by running the EM algorithm on a given dataset.
TODO:
Acceleration:
Aitken acceleration
numba
Notes on the derivation of the posterior distribution of β: Let g(β)=−21(y−Zω−Xβ)T(σe2In)−1(y−Zω−Xβ)−21βT(σβ2Ip)−1β. Then we have ∇g(β)=XT(y−Zω−Xβ)/σe2−β/σβ2. Let ∇g(β)=0, we have β=ΓXT(y−Zω)/σe2, where g(β) is maximized. Thus, we find the μ. To obtain the variance of β, we need to calculate the Hessian matrix of g(β) and evaluate it at β=μ. The Hessian matrix is given by ∇2g(β)=XTX/σe2+Ip/σβ2. Therefore, the variance of β is Γ=(σe2XTX+σβ2Ip)−1. ↩︎
log∣Σ∣: Directly calculate the log determinant of Σ would cause numerical overflow:RuntimeWarning: overflow encountered in reduce return ufunc.reduce(obj, axis, dtype, out, **passkwargs) That's because "If an array has a very small or very large determinant, then a call to det may overflow or underflow". When the dimension of Σ is large, ∣Σ∣ would be extremely close to zero so that it may be considered as zero by numpy. Therefore, we use log∣Σ∣=∑i=1nlogλi to calculate the log determinant of Σ. ↩︎
When calculating the eigenvalue decomposition, it's better to use 'numpy.linalg.eigh' instead of 'numpy.linalg.eig' since Γ~ is a real symmetric matrix. The former is faster and more accurate than the latter. ↩︎